文章导航目录
- 第一章:OCR技术原理与WPS优势
- 第二章:基础识别操作全流程
- 第三章:多语言识别与高级设置
- 第四章:版面保持与格式还原
- 第五章:批量OCR处理技巧
- 第六章:准确率提升策略
- 第七章:行业应用场景实例
- 第八章:常见问题解决方案
- 第九章:未来发展趋势
第一章:OCR技术原理与WPS核心优势
光学字符识别(OCR)技术通过图像处理、模式识别和人工智能算法,将图片中的文字转换为计算机可处理的文本数据。WPS集成了最新的深度学习OCR引擎,在准确率和效率方面具有显著优势。
图像输入
扫描PDF或图片文件
预处理
降噪、二值化、倾斜校正
字符分割
分离单个字符
特征识别
AI模型识别字符
结果输出
可编辑文本文件
AI智能识别引擎
基于深度神经网络训练,支持数千万字符样本库,能够准确识别复杂字体、低分辨率文字和混合排版内容。特别优化了中文竖排、古籍字体等特殊场景的识别能力。
高性能处理架构
多线程并行处理技术,充分利用多核CPU性能,单页处理时间控制在2-5秒内。支持GPU加速选项,在处理大量文档时效率提升300%以上。
WPS OCR独特优势
一体化集成:无需安装第三方软件,直接在WPS中完成所有操作
格式保持优秀:表格、图文混排等复杂版面还原度达95%以上
离线识别能力:核心识别引擎支持离线工作,保护数据隐私
云服务增强:可选云OCR服务,识别准确率进一步提升
第二章:基础识别操作全流程
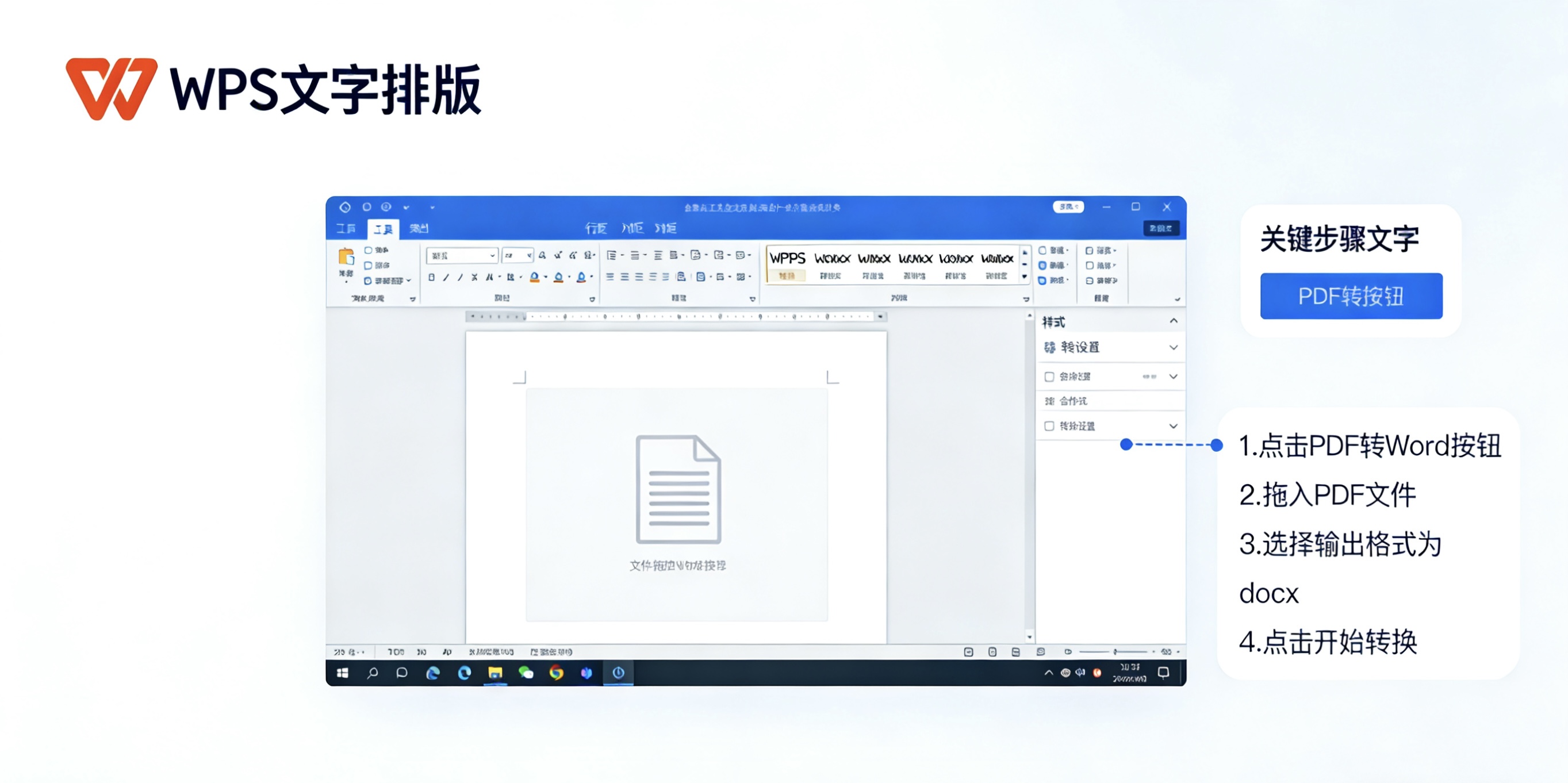
单文件OCR识别步骤
1打开PDF文件
在WPS中打开需要识别的扫描PDF或图片文件,支持格式:PDF、JPG、PNG、BMP、TIFF。
2进入OCR功能
点击顶部菜单栏"转换" → "PDF转Word" → 选择"OCR识别"模式,或直接使用右侧工具栏OCR按钮。
3设置识别参数
在弹出的OCR设置窗口中:
4预览与调整
使用预览功能检查识别效果,可调整识别区域、排除无关内容。
5开始识别
点击"开始识别"按钮,进度条显示处理状态,大型文档支持暂停和继续。
6保存结果
识别完成后自动打开Word文档,检查识别准确性后保存到指定位置。
识别效果对比示例
原始扫描内容:
(这是一份扫描的会议纪要,文字清晰度中等)
识别后文本:
2024年第一季度项目会议纪要
会议时间:2024年3月15日 14:00-16:30
参会人员:张三(项目经理)、李四(技术总监)、王五(产品经理)...
会议议题:1. 项目进度汇报 2. 技术难点讨论 3. 下一阶段计划
决议事项:1. 增加测试资源投入 2. 调整项目时间节点 3. 更新需求文档...
第三章:多语言识别与高级设置
多语言支持能力
WPS OCR支持23种主流语言的混合识别,特别优化了东亚文字处理:
高级参数配置
识别精度调节:标准、精确、快速三种模式
字符集选择:自定义字符集提高专业文档识别率
版面分析:自动/手动版面分析选项
输出控制:文本编码、换行符、制表符设置
| 语言类型 | 识别准确率 | 处理速度 | 特殊支持 |
|---|---|---|---|
| 简体中文 |
99%
|
2秒/页 | 竖排识别、古籍字体 |
| 英文 |
99.5%
|
1.5秒/页 | 连字符处理 |
| 日文 |
98%
|
2.5秒/页 | 假名汉字混合 |
| 韩文 |
97%
|
2.2秒/页 | 韩汉混排 |
第四章:版面保持与格式还原
复杂版面处理技术
WPS OCR采用先进的版面分析算法,能够智能识别和保持文档的原始结构:
1. 多栏文本处理
自动识别报纸、杂志等多栏排版,保持分栏结构不变
2. 表格识别还原
识别表格线框,转换为可编辑Word表格,保持行列结构
3. 图文混排保持
精确定位图片位置,文本环绕效果自动还原
4. 页眉页脚处理
识别并保持页眉页脚内容,避免与正文混淆
5. 字体样式识别
识别粗体、斜体、下划线等文本样式并保留
版面优化技巧
区域选择识别:对复杂版面,手动选择识别区域提高准确性
分步处理:文字和表格分别识别再组合
模板匹配:对固定格式文档创建识别模板
后处理校正:识别后使用WPS校对工具批量修正格式
第五章:批量OCR处理技巧
批量处理工作流
文件夹批量识别:指定输入文件夹,自动处理所有PDF/图片
队列处理:添加多个文件到处理队列,顺序执行
模板应用:对同类文档应用相同识别设置
结果合并:多个识别结果自动合并为单个文档
自动化配置
计划任务:设置定时自动执行OCR任务
监控文件夹:监控指定文件夹,新增文件自动识别
条件处理:根据文件属性决定处理方式
日志记录:详细记录每个文件的处理状态和结果
第六章:准确率提升策略
识别前优化准备
1. 图像质量优化
• 分辨率要求:至少300DPI
• 对比度调整:确保文字与背景清晰区分
• 去噪处理:移除扫描斑点、阴影
2. 文档预处理
• 页面纠偏:自动校正倾斜页面
• 边框裁剪:移除扫描黑边
• 分页优化:确保每页内容完整
3. 识别参数调优
• 选择正确语言包
• 调整识别敏感度
• 设置自定义字符集
影响识别准确率的因素
图像质量问题:模糊、低分辨率、光照不均、阴影遮挡
字体特殊性:艺术字、手写体、极小字号、特殊符号
版面复杂性:密集表格、图文重叠、背景干扰、多语言混排
文档状况:陈旧纸质、墨水褪色、折叠痕迹、装订遮挡
第七章:行业应用场景实例
教育科研领域
古籍数字化:历史文献、古籍扫描件转可搜索文本
论文管理:扫描版论文转换为可编辑文档
试卷处理:纸质试卷电子化存档和分析
图书管理:制作电子书、建立全文检索库
企业办公场景
合同管理:扫描合同转换为可搜索数据库
档案数字化:历史档案电子化保存
财务处理:发票、收据信息提取
会议记录:纸质会议记录电子化归档
政府机构应用
公文处理:历史公文数字化存档
户籍档案:纸质档案电子化管理
证照识别:身份证、营业执照信息提取
审批材料:纸质申请材料电子化处理
实际应用案例
某图书馆项目:使用WPS OCR处理10万页古籍,识别准确率达96.5%,制作时间缩短80%
某企业档案室:批量处理5年历史合同,建立全文检索系统,查询效率提升95%
某政府部门:数字化处理20年历史公文,实现电子化归档和智能检索
第八章:常见问题解决方案
问题一:识别结果乱码或错位
可能原因:语言设置错误、编码问题、版面分析失败
解决方案:
1. 检查并正确设置识别语言
2. 尝试不同编码格式(UTF-8、GBK等)
3. 使用手动版面分析功能
4. 降低识别速度以提高准确性
问题二:表格识别不准确
优化策略:
1. 预处理时加强表格线检测
2. 选择"表格优先"识别模式
3. 手动划定表格区域
4. 识别后使用WPS表格工具校正
问题三:处理速度过慢
性能优化方案:
1. 降低图像分辨率至300-400DPI
2. 启用GPU加速(如果显卡支持)
3. 减少同时处理文件数量
4. 关闭实时预览功能
第九章:未来发展趋势与技术展望
AI技术深化
• 更精准的手写体识别
• 复杂场景自适应学习
• 多模态内容理解
• 实时识别处理能力
云服务集成
• 云端大规模数据处理
• 多端同步识别
• 协同编辑支持
• 智能归档管理
智能化升级
• 自动文档分类
• 智能摘要生成
• 内容关系挖掘
• 个性化识别优化